
Vous n’êtes pas sans savoir qu’il y a eu un terrible incendie au Port du Rhin le 10 mars 2021 à Strasbourg, sur le site d’OVHcloud. Je vous propose un retour d’expérience étant un client affecté.
Les faits.
Je me lève un beau mercredi matin avec ça :
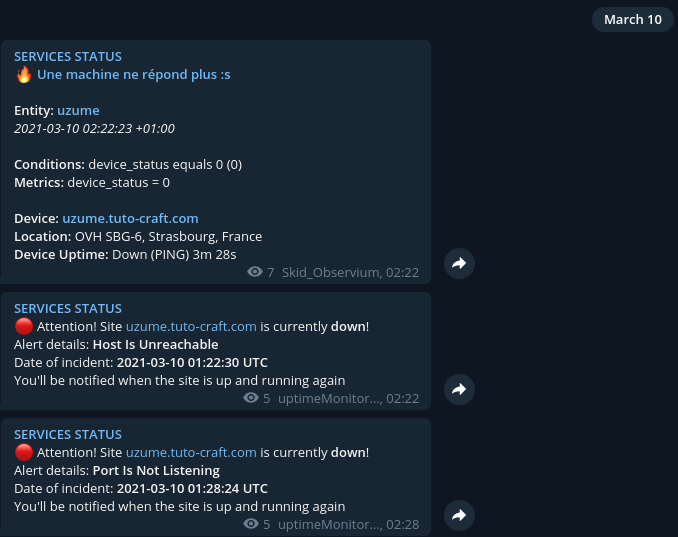
(Voyez le choix très smart de l’emoji sur mes alertes observium…)
Un peu encore dans les choux (4h de sommeil, faut pas trop m’en vouloir), je vérifie que c’est pas juste ma stack de monitoring qui est plantée, mais non, ça répond plus à rien, ICMP, SSH, HTTP, nope, que dalle.
Pour contexte, c’est ma vm off-site (donc hors de chez moi) avec le plus de services dessus, y a du web, du mail, y a des apps randoms qui me servent, etc…J’avais quelques moi plus tôt pris la décision de mettre mon DNS autoritaire principal sur une autre vm également chez OVHcloud mais cette fois à Gravelines.Le choix de Strasbourg en principal venait surtout du fait que j’y habite et que je considérait Roubaix comme un énorme SPOF.
Puis j’ouvre Twitter (crédits photos SDIS67 - Pompiers du Bas-Rhin) :




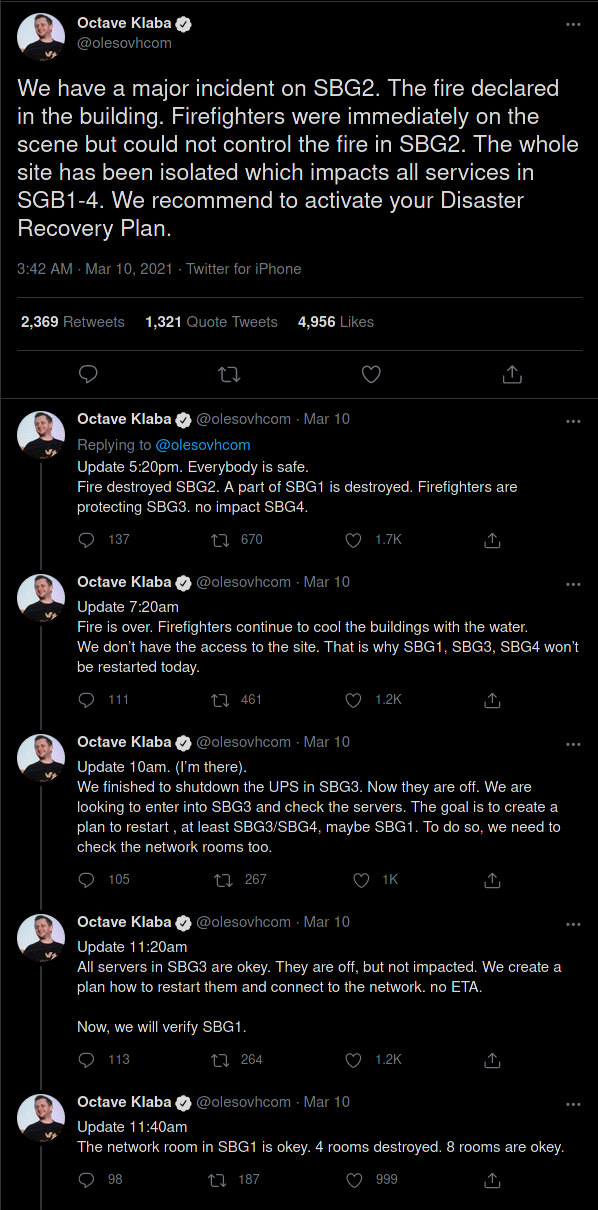
Il y a eu donc un départ de feu dans une salle d’SBG2, a priori sur des onduleurs qui avait subis une maintenance avec un remplacement de pièces. Le feu n’a pas été maîtrisé par les équipements et les équipes sur place.
Appel des pompiers par OVHcloud, qui ne peuvent pas agir immédiatement, il y a toujours de la très haute tension (20kV) active sur le site, ni OVHcloud ni ÉS (Électricité de Strasbourg) ne l’avais coupé en interne ou en amont.C’est seulement après coupure que les pompiers ont pu agir.
Bilan des courses sur 4 structures :
- SBG1 (conteneurs) : Partiellement détruit
- SBG2 (tour) : Intégralement détruit
- SBG3 (bâtiment) : Sauvé intégralement par les pompiers
- SBG4 (conteneurs) : Aucun dégât à signaler
Mais comment sont agencées ces structures pour qu’il y ait autant de dégâts ? Voyons ça en image.

https://www.openstreetmap.org/#map=20/48.58583/7.79747&layers=T
Sur cette image satellite on peut voir de bas en haut, SBG de 1 à 4, on remarque que chaque structure est connectée à une autre, sûrement pour faciliter les déplacements du personnel sur place.

Image qu’on peut recoller par cette photo prise par les pompiers avec pour seul changement, SBG5, en construction, que l’on peut voir à l’extrême gauche de la photo.
Disclaimer : Je ne suis pas expert en conception de datacenter, je ne commenterais pas le choix des design d’OVHcloud (bien, pas bien) simplement car ce n’est pas mon métier, je propose seulement ma compréhension de ce qu’il s’est passé.Également, je ne touche rien à leur dire du bien, je suis simplement client, si quelque chose va pas je le dis et inversement.
SBG2 étant basé sur un design de freecooling (donc pas de climatisation active), toute la chaleur est évacuée par le centre, ce qui donne un effet “cheminée”.C’est donc à double tranchant, d’un côté, une grosse économie de climatisation, mais de l’autre en cas d’incendie, le design aggrave les dégats.
De plus, au delà de l’effet cheminée, celà empêche l’usage de méthodes d’extinction automatiques comme on peut le voir dans d’autres datacenters, comme l’usage du FM200 (gaz) par exemple, les salles étant ventilées en permanence, l’usage du gaz n’aurait produit aucun effet vu qu’il ne serait pas confiné dans la/les salles.
Après ont-ils une autre méthode d’extinction automatique ? Mystère et boule de gomme, mais a priori, ça n’a pas marché.
En voyant les photos, c’est une évidence de pourquoi SBG1 a été à moitié détruit, par contre ça relève du miracle (et de la compétence des pompiers) que la structure d’SBG3 n’ait pas été affectée.
Chose à noter cependant, il y eu beaucoup de critiques sur l’usage de planchers (voir même de structure) en bois pour SBG2, hors si le bois est traité, ce n’est pas tant que ça un problème, on remarque d’ailleurs que le bâtiment, malgré les températures extrêmes, ne s’est pas écroulé.
Round 2
Vendredi 19 mars, nouveau départ de feu, dans un local de SBG1, mais cette fois-ci maîtrisé.La presse fait part d’un incendie tandis qu’OVHcloud ne parle que de fumées, pour l’heure, aucune des deux version n’a pu être vérifiée.Chose sûre cependant, les pompiers se sont re-déplacés sur le site.
Suite à ça, changement radical de plans, fermeture définitive d’SBG1, les serveurs encore vivants seront transplantés à SBG3 et 4 après nettoyage à Croix.


Encore aujourd’hui, cet incident n’est pas terminé, il reste encore beaucoup de serveurs à nettoyer beaucoup à reconstruire et des racks à allumer.
Et moi dans tout ça ?
Et bien il a fallu que je sache où je me trouve, ou plutôt où ma vm se trouve.
“SBG6”, sauf qu’il n’existe pas de bâtiment SBG6 !
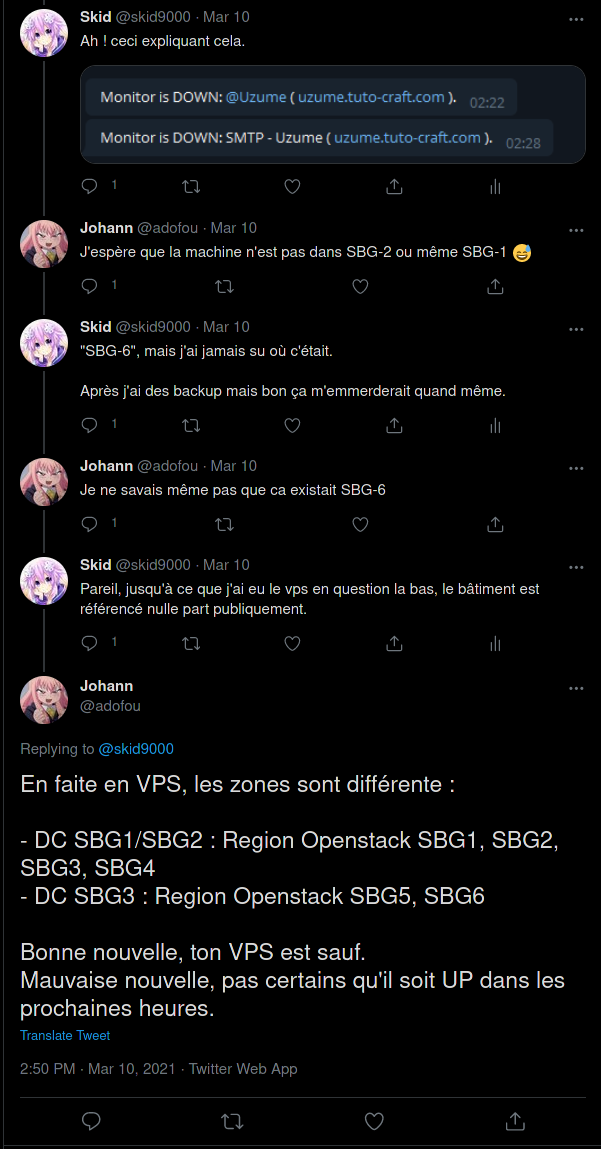
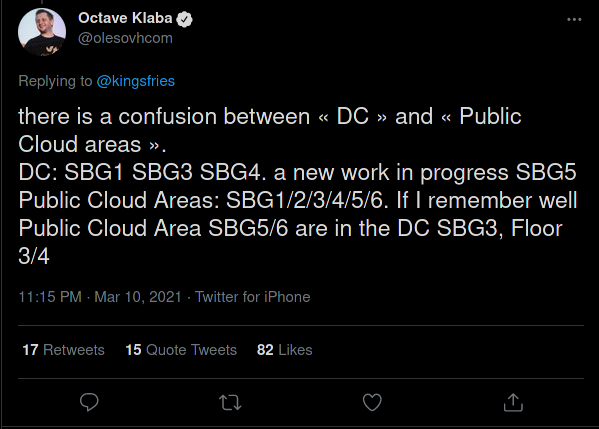
Bonne nouvelle ! Mon VPS était sauf ! Mais j’allais pas attendre des jours que ça remonte, mes services j’en ai besoin.Je prend donc une vm sur Vultr, et je restaure la dernière backup en date (du jour précédent l’incendie, mes backups se font à 4h du matin, la vm s’était éteinte vers 2h30~), quasiment pas de pertes, si ce n’est 4-5 mails dont je n’avais pas besoin en urgence, donc tout va bien !J’abaisse le TTL des records A (IPv4) et AAAA (IPv6) de uzume.tuto-craft.com à 3600 secondes, je change les adresses et voilà, quasiment tout était de nouveau en ligne et ce en moins de 24h.

Je réalise mes backups avec borg (qu’on utilise également chez Anjara !) et je les héberge sur un espace de stockage chez l’hébergeur Allemand Hetzner, à Falkenstein (11,78€ TTC/mois les 2 To ? Imbattable).
C’est clairement perfectible, mais pour un usage perso c’est déjà pas mal.
21 mars, ma vm est de nouveau en ligne à SBG3 ! En même temps, je prend la décision de séparer mes services mail sur une autre vm chez Vultr, l’ip n’étant pas blacklistée par Microsoft…
La c’était pas compliqué, on coupe la cron des backups temporairement et je passe un rsync des dossiers qui ont changés, et en 3h tout était de nouveau sur OVHcloud ! Le TTL de mes records étant à 3600 secondes (1h), je l’ai baissé à 300 secondes (5 minutes), je patiente une heure, je rechange les adresses et je remonte le TTL à 3600 secondes.
N’étant pas certain de si un autre incident allait se produire, j’ai gardé le TTL à 3600 le temps d’une semaine, puis je l’ai remonté à 86400 secondes (24h).
Maintenant on est mi-avril et de mon côté, tout va bien, ma facture de mars s’est faite annulée et j’ai reçu un premier mois gratuit en avoir, j’attends encore les deux suivants promis.
La magie du cloud.
Ce qui est marrant quand on vend du “cloud” c’est que généralement les gens (particuliers, entreprises, le chat de ton voisin) ils comprennent rarement ce qu’ils achètent et ça, suffit encore une fois d’ouvrir Twitter pour le constater :
Ça va de la simple inaccessibilité temporaire :
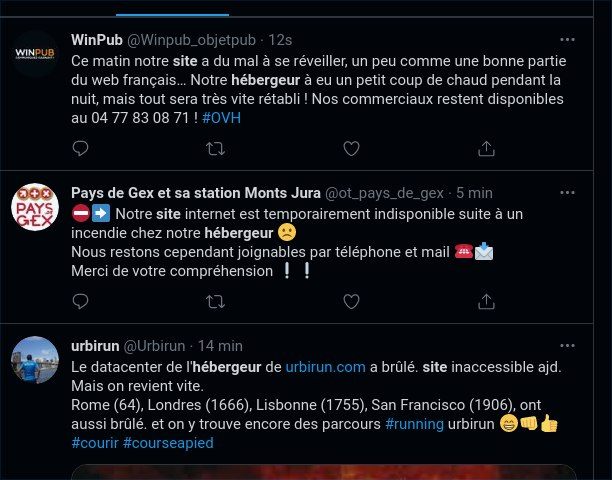
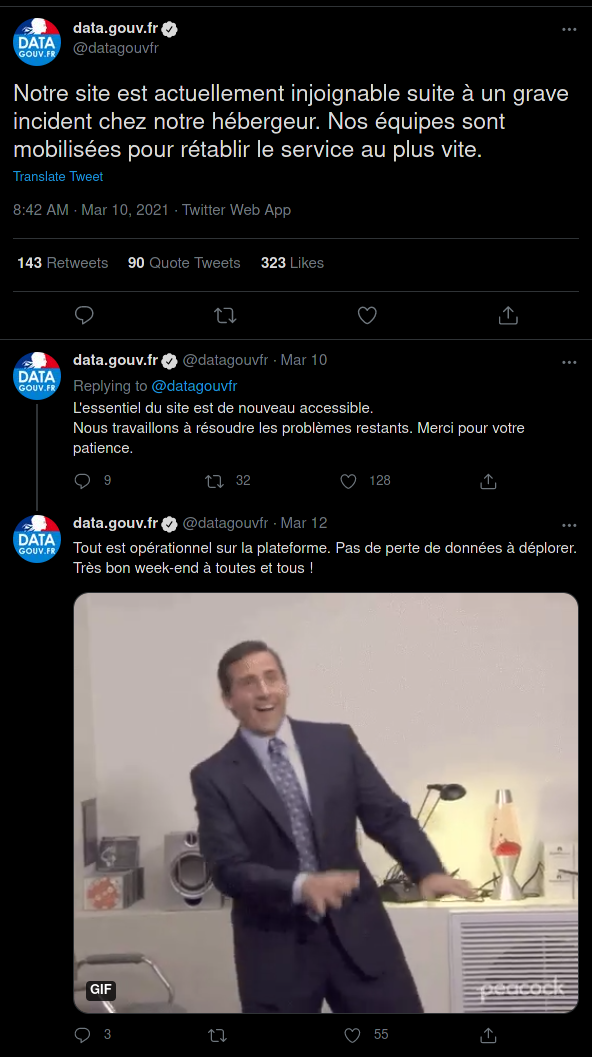
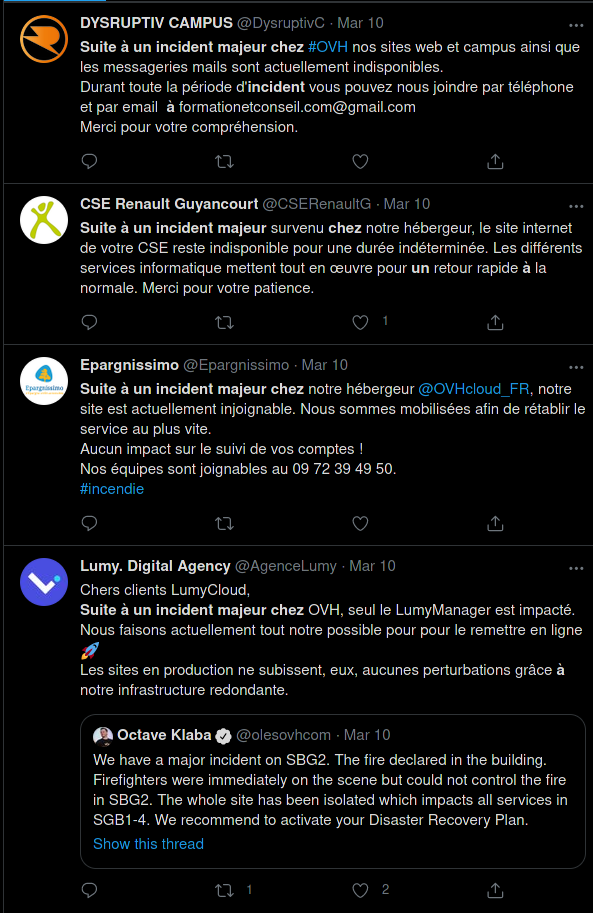
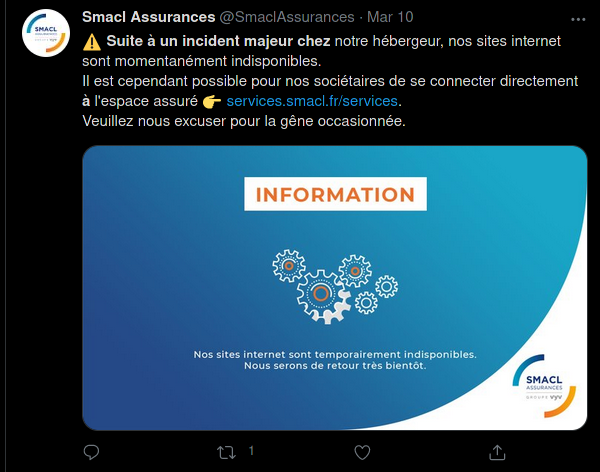
Ça la fout quand même mal pour une assurance.
Aux personnes frustrées :
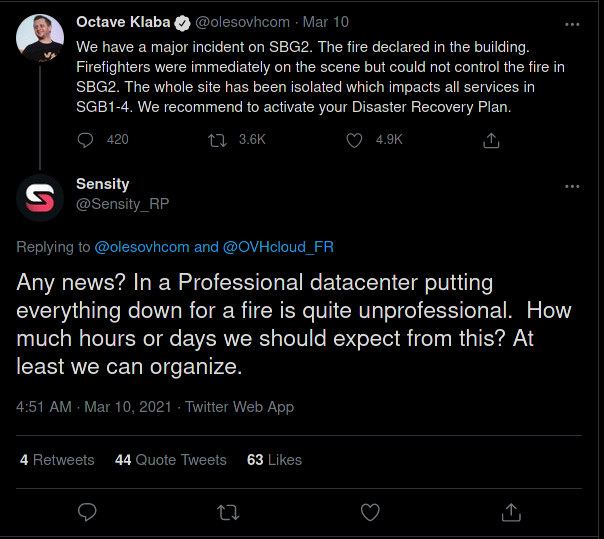
Ja, il est vrai que ton serveur FiveM RP est une priorité absolue qui doit sûrement faire des millions chaque seconde !
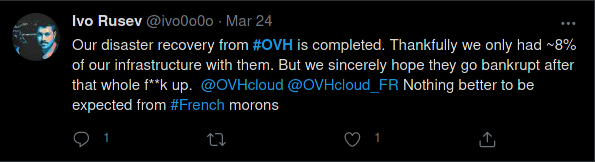
Sympa !
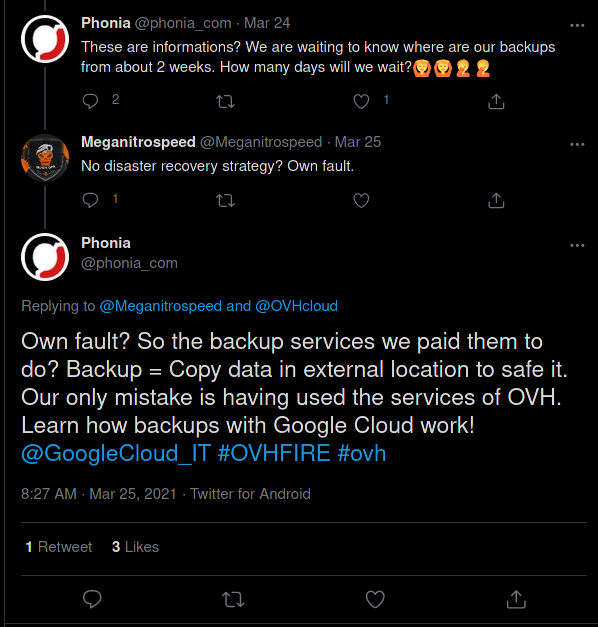
Ne_pas_savoir_lire_un_contrat.png
Aux personnes, euh, hors catégorie :


Soit un hébergement à 5€ par mois, pour un CA de 8000€ / mois, lol.
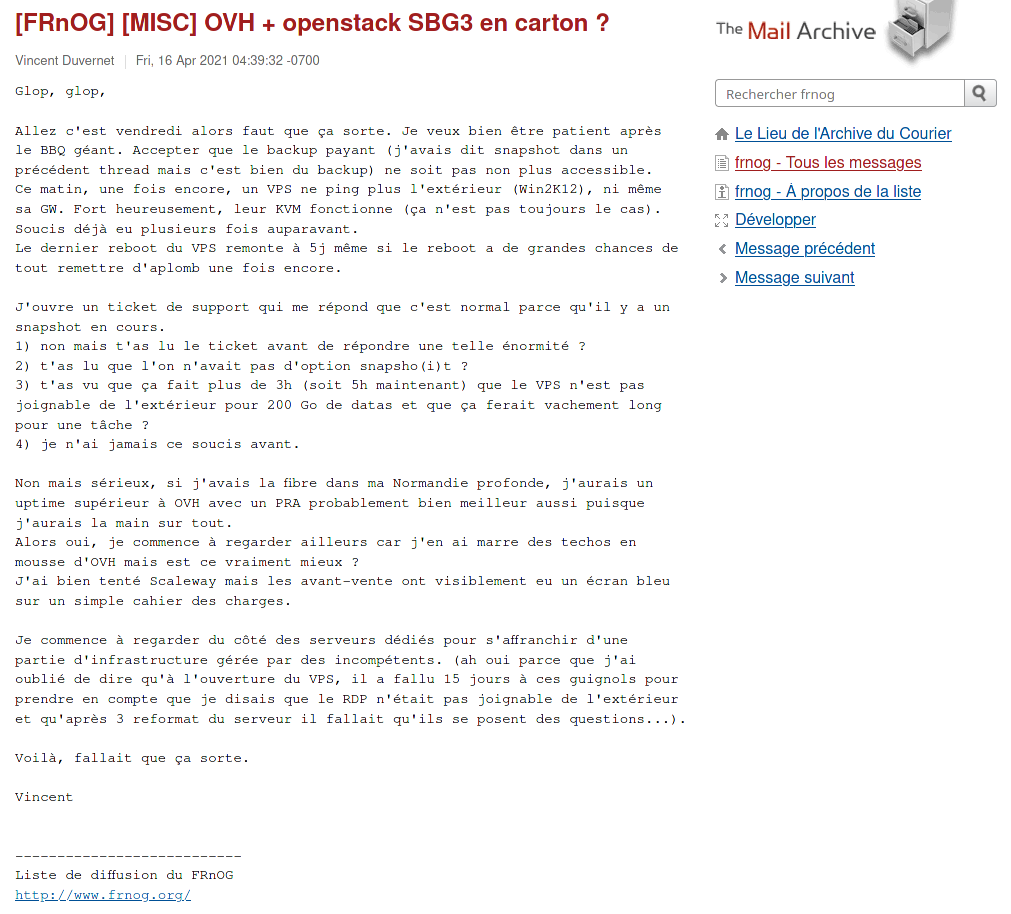

Oh ils sont mignons.

Qu’en penser ?
Administrateur système, ça s’improvise pas et on le remarque bien avec cet incident.
D’un côté les gens qui ont bien fait leurs backups off-site et dont le plan de reprise d’activité à fonctionné et de l’autre soit pas de backup du tout ou alors backups on-site, qui sont soit cramées soit hors-ligne.
Pour la première catégorie, rien à dire, ils ont tout compris (sans pour autant être chez Free).Pour la seconde c’est là qu’on voit que pas mal de personnes négligent ou ignorent complètement les backups.
Il y a la polémique sur les backups payantes dont une partie serait HS car sont on-site.Globalement de ce que j’ai suivi :
Les anciennes offres (au niveau contrat) stipulent que le service de backup est présent sur le même site que le service associé, elles sont là pour des incidents mineurs, comme un défaut matériel par exemple.Ce n’est pas le cas des nouvelles, où les backups sont sur des zones géographiques différentes.
Reste à savoir si l’information pour ces anciennes offres est vraie et si c’est le cas, il y a sûrement des gardes fous dans le contrat pour des cas de force majeur, mais ne l’ayant pas, ça reste à voir.
Autrement et surtout au delà du service proposé par OVHcloud, c’est quand même affligeant de voir des DSI complètement au chômage car aucune backup off-site n’avait été faite pour des infrastructures qui font tout ou partie le chiffre d’affaire de l’entreprise.
Trois données = deux réelles, deux = un, et un = zéro.Si vous n’avez pas au minimum une backup hors-site, considérez que vous n’avez juste plus rien.
Si pour mes besoins perso et avec un budget étudiant j’ai pu le faire, une TPE, PME, Grande entreprise ou autre structure peut largement se le permettre.
Côté OVHcloud, c’est sûr, ils ont leur part de responsabilité, mais je trouve qu’il est encore bien trop tôt pour leur mettre l’intégralité de l’incident sur le dos, du moins tant que l’enquête ne sera pas terminée et publiée (ce que compte “a priori” faire OVHcloud).
Par contre, même si c’est pas toujours très clair, l’effort de communication d’OVHcloud, au travers de son ex-PDG Octave Klaba est quand même remarquable.Vous seriez chez AWS, vous auriez probablement jamais su que le datacenter avait brûlé.
Conclusion
Vérifiez vos backups, vérifiez vos PRA et PCA et si vous n’en n’avez pas, il est grand temps de le faire :)
Si OVHcloud ne va pas “faire changer les standards de l’industrie”, j’éspère que cet incident va changer les mentalités de certain(e)s.
Le “cloud” ça n’a rien de magique, il y a et il y aura toujours des infrastructures et de l’humain, quel que soit le service.
Merci à leonekmi pour la relecture :)