
Depuis le temps que j’en parle, que c’est déjà arrivé à plusieurs reprises pour des raisons différentes mais que les gens continuent quand même dans le même sens sans se poser de questions, y a des fois je me demande si ce que j’écris fait encore un sens, mais bon au moins vous aurez mon avis sur le sujet :).
Ce vendredi soir (17/07/2020) on aura eu une belle surprise de découvrir qu’un grand acteur s’est joliment viandé de partout, Cloudflare pour pas les citer, ce qui a rendu inopérant une bonne partie d’internet utilisant leurs services (réseau / dns / grille pain / whatever).
Dans la liste des services utilisant Cloudflare d’une manière ou d’une autre on peut compter Discord, Crunchyroll, Patreon, npmjs, DigitalOcean, Coinbase, Zendesk, Medium, Gitlab, Fiverr, Upwork, Udemy, DownDetector (lol) et j’en passe.
Cloudflare a posté un post-mortem de l’incident ici mais plutôt s’atteler au pourquoi ça a explosé (Cloudflare a pour le coup fait un bon job explicatif de manière transparente), on va pour commencer réexpliquer un truc basique qui s’applique à tout le monde :
JAMAIS AU GRAND JAMAIS TU PUSH EN PRODUCTION UN VENDREDI
TL;DR : En tentant de corriger un problème qui n’avais rien avoir, une erreur de configuration s’est glissée ce qui aurait leak une grosse partie des routes BGP vers un routeur à Atlanta et globalement, le routeur a fondu avec traffic qu’il s’est mangé.
Mais du coup que peut on retenir de cet indicent ?
Centraliser les ressources chez le même acteur, quel qu’il soit, est une pure bétise, aucun acteur est infallible.
Le cas de Cloudflare est plus extrême que tout les autres du simple fait que leur reverse proxy “Anti DDoS” est devenu extremement populaire (surtout par sa grille tarifaire).Avec le nombre de gens qui ne font pas confiance à l’anti DDoS local (hébergeur, opérateur, whatever), ça s’est vite répendu, au point où dès que ça tombe on le remarque assez rapidement.
Assurément, il ne s’agit que d’un seul service parmit la flopée qu’ils proposent, on peut compter nottament du dns authoritaire, resolveur dns (one.one.one.one), CDN, Load balancers, etc…
Plein de trucs que l’on peut déployer en propre soit même pour même pas si cher que ça.
Les DNS authoritaires sont un exemple que je reprend souvent, mais avoir plusieurs NS sur des AS différents n’est pas si compliqué.
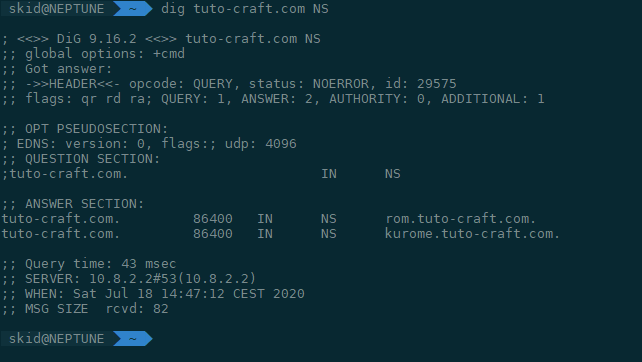
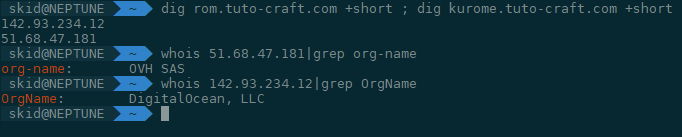
Si j’ai pu le faire, je suis certain que d’autres en sont capables.
C’est pas complexe non plus de monter son propre résolveur (avec Unbound par exemple), ou simplement d’utiliser un résolveur un peu plus local (FDN ou LDN en France par exemple).
Pour ce qui est de l’Anti-DDoS, les bons acteurs de l’hébergement ont déjà du matériel en Datacenter pour ça, qui pour une majorité, est largement suffisant.Je peut vous garantir qu’on a pas attendu Cloudflare pour faire de l’Anti-DDoS qui marche, demandez à Acorus Network ou à Arbor :)
Enfin bref on l’a bien vu Vendredi, cet incident, d’une ampleur plutôt imprésionnante, c’est un truc qui aurait pu arriver à n’importe qui, dont Cloudflare. Centraliser tout chez eux ou chez n’importe quel acteur reviens à avoir un SPOF (Single Point Of Failure) dans votre infrastructure et surtout continuer à alimenter un des quelques SPOF d’internet de manière plus générale.
Conclusion ?
Tout ce que vous pouvez self-host, faîtes le ! Si vous avez les moyens redondez tout sur plusieurs AS, dans différents pays voir continents, c’est le meilleurs moyen de limiter la casse en cas de bourde chez certains acteurs.